
학습 데이터는 1로 라벨링된 887개의 정탐과 0으로 라벨링된 6,700여 개의 오탐이 섞인
 |
| 정탐 |
 |
| 오탐 |
모델 학습
학습 데이터를 sqland-learning이란 인덱스에 저장 후, Machine Learning > Data Frame Analysis > Create analytics job 메뉴 클릭.
① 작업 유형은 classification(decision tree 알고리즘 사용), ⑤ dependent variable(종속 변수)은 라벨링 필드를 선택. 참고로 classification은 문자형, ourlier/regression은 숫자형 데이터에 적용 가능한 듯하다.

작업 완료 후, view 메뉴를 클릭하면 학습 결과를 볼 수 있다. 1을 1로 판단한 정탐률은 27%, 0을 1로 판단한 오탐률은 7%. 1을 0으로 판단한 미탐률은 73%. 일일이 라벨링 해줘도 많이 어려운 모양(..)

모델 테스트
테스트 데이터는 14개의 정탐이 포함된 2,009개의 sql injection 탐지 로그. CSV 형식 데이터는 로그스태시 없이도 Machine Learning > Data Visualizer(Import data) 기능을 이용해서 간단하게 연동할 수 있다.

① Override settings 메뉴를 이용해서 필드 이름 수정, ② Advanced 메뉴를 이용해서 학습 모델 적용을 위한 ingest pipeline 설정 추가 후 임포트.

ingest pipeline에 사용된 학습 모델 정보는 Dev Tools 메뉴에서 확인할 수 있다.

테스트 결과
sqland-test라는 인덱스를 만들면서 sql injection 학습 모델을 적용했으며, 그 결과는 ml.inference.predicted_value 필드에 기록된다.

sql injection 14개 모두 놓침. -_-

학습 데이터가 너무 오탐(정상 uri)에 치중돼서 그런가?
학습 데이터 수정
IDS 로그의 정오탐 비율을 1:1로(각각 887개) 수정 후, 바뀐 데이터로 재학습. 0을 1로 판단한 오탐률만 7%에서 3%로 감소.

혹시나 하면서 새 모델을 적용했지만 역시나(..)

sql injection 로그 14개만으로 테스트해도 결과는 마찬가지. 기계가 보기엔 sql injection 패턴이 포함된 uri나, 정상 uri나 다 비슷해보이는 모양.

학습 데이터가 너무 적나? sql injection 패턴이 삽입되는 변수 영역만 따로 분리해볼까?
관련 글
IDS 로그의 정오탐 비율을 1:1로(각각 887개) 수정 후, 바뀐 데이터로 재학습. 0을 1로 판단한 오탐률만 7%에서 3%로 감소.
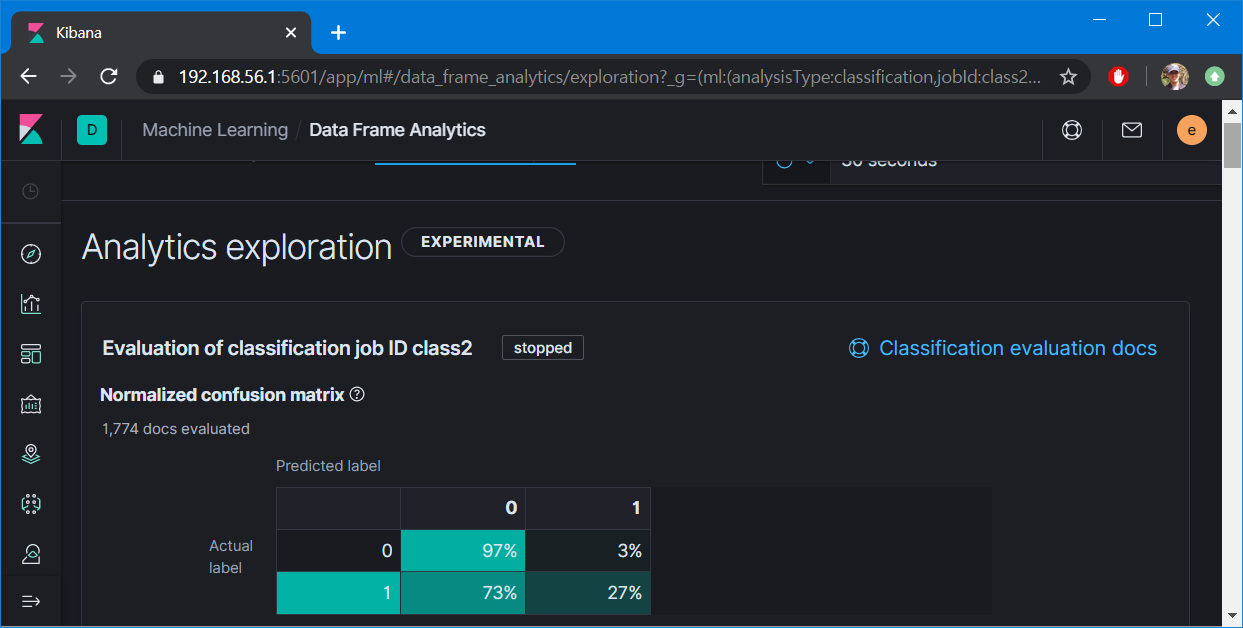
혹시나 하면서 새 모델을 적용했지만 역시나(..)

sql injection 로그 14개만으로 테스트해도 결과는 마찬가지. 기계가 보기엔 sql injection 패턴이 포함된 uri나, 정상 uri나 다 비슷해보이는 모양.

학습 데이터가 너무 적나? sql injection 패턴이 삽입되는 변수 영역만 따로 분리해볼까?
관련 글

댓글 없음:
댓글 쓰기