
 |
| 정탐 |
 |
| 오탐 |
정오탐 각각 8백여 개일 때와 큰 차이 없는 학습 결과.

테스트1
다음은 학습에 사용했던 데이터를 이용한 모델 테스트 결과. 딱 학습 결과만큼의 정확도를 보여준다.
 |
| 정탐 |
 |
| 오탐 |
 |
| 미탐 |
테스트2
다음은 학습 데이터의 sql injection 패턴을 살짝 변형('%20and%20' -> '%20or%20')해서 테스트한 결과. 패턴이 달라지니 정탐률이 감소한다. 그래도 학습량 늘리니 모델이 조금은 유연해진 느낌? 하지만 23%의 오탐과 6%의 미탐 때문에 욕먹겠지?
 |
| 정탐(94%) |
 |
| 오탐(23%) |
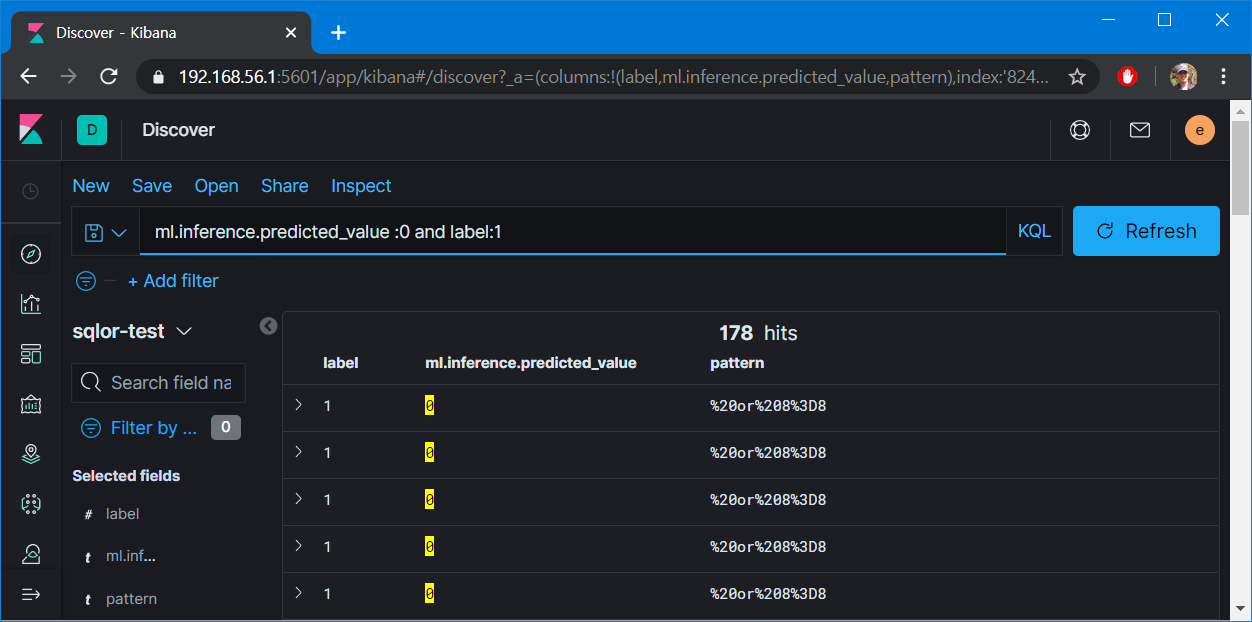 |
| 미탐(6%) |
테스트3
과거 테스트 데이터(14개 정탐이 포함된 데이터 2009개)에도 적용해봤다. 과거 모델(정오탐 각 8백여 개, 정탐률 98%)을 사용했을 때는 겨우 정탐 하나 건졌었는데, 새 모델(정오탐 각 3천여 개, 정탐률 97%)로 바꾸니 하나 빼고 전부 탐지.
 |
| 정탐 |
문제는 오탐도 대박(..)
 |
| 오탐 |
테스트 결과는 학습한 데이터에 대해서는 머신러닝이 제법 잘 동작한다는 사실을 알려준다. 학습을 얼마나 많이, 잘 하느냐가 관건. 하지만
어차피 사람도 실수를 하니 그냥 운에 맡겨? 아니면 사람이 최종 검증하는 프로세스 추가? 결국 문제 터졌을 때 총대 매겠다는 사람 나오지 않는 이상, 사람이 하던 일은 계속 하게 되지 않을까 싶다.
룰은 계속 만들어질테니, 스스로 학습하는 인공지능이 나오기 전까지 학습 데이터는 계속 만들어줘야겠군. 그런데 이왕 만든 학습 데이터로 룰도 개선해보면 어떨까? 룰이 정확해지면 오탐이 줄테고, 덩달아 로그양도 줄테고, 그러면 수백, 수천 만 개의 로그에서 공격을 찾아 헤매는 일도 줄텐데. 가만 그러면 인공지능 할 일이 없어지겠네!?
관련 글

댓글 없음:
댓글 쓰기