
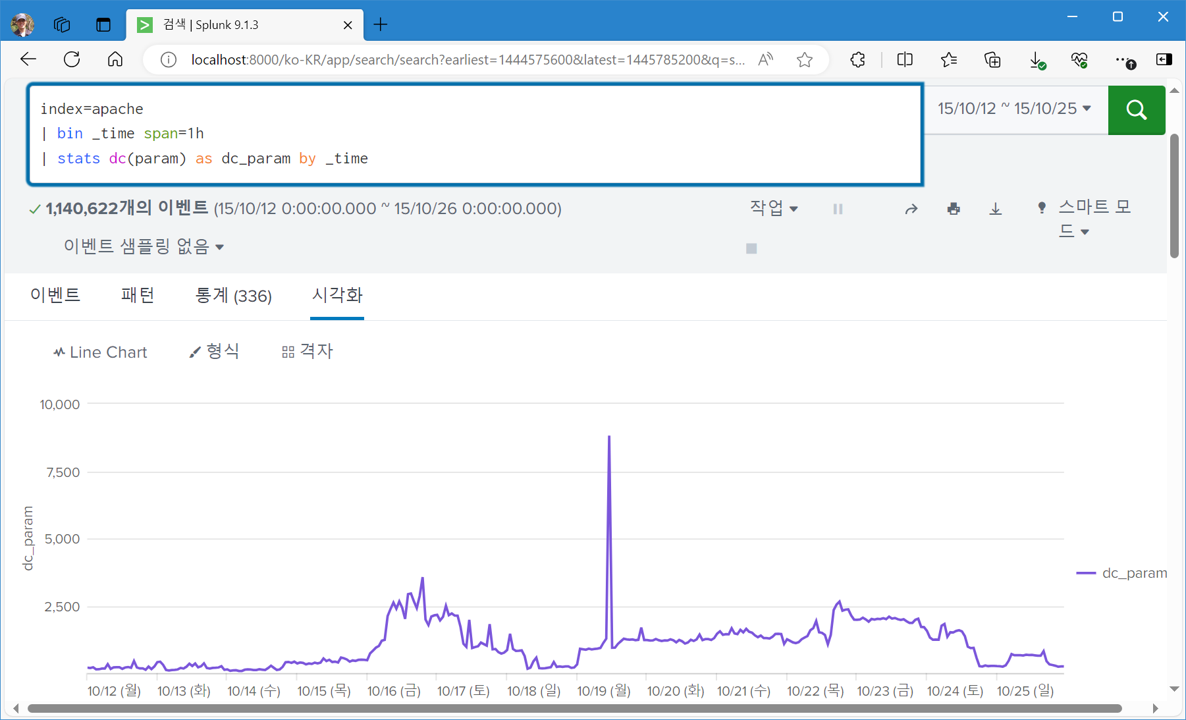
스플렁크는 데이터 이상징후 분석 기능을 제공한다. 그중 발생 빈도, 표준편차 등의 계산 방식으로 비정상 정도를 산정한다는 anomalousvalue에 변수 고유개수 분석을 맡겨봤다.



미탐 50%, 오탐 50%.

다음은 머신러닝 알고리즘 중 하나인 DensityFunction 적용 결과. anomalydetection과 결과는 같은데, 검색 비용은 약 3배 증가. (fit 명령어는 MLTK 설치 후 사용 가능)


컴퓨팅 비용 증가를 감수할 수 있으면 표본 늘려서 미탐율을 줄일 수도 있다. 아니면 빡공해서 최적의 명령어 셋팅 조합을 찾을 수도 있고. 그런데 굳이 그럴 필요가 있을까? 웹로그 구조를 알면 그냥 갯수만 세도 상태가 보이는데(..)

그래야 알아주는 세상이 돼버렸다
이때 중요한 건 목적과 도구의 구분. 목적이 뚜렷하면 어떤 데이터가 필요한지, 그 데이터를 어떻게 계산할지에 대한 결정이 가능해지고, 계산 결과가 진짜 원했던 것인지 고민해볼 수 있는 기회를 얻게 된다.
그런 고민이 더해지면 계산은 점점 더 정확해지고. 머신러닝은 그 과정에서 계산을 도와주는 툴일 뿐. 결국 데이터가 알고리즘을 이긴다.

댓글 없음:
댓글 쓰기