
- 후방탐색을 사용하지 않은 정규표현식 'referer:\s\S\+'의 검색 결과

- 후방탐색을 사용한 정규표현식 '\(referer:\s\)\@<=\S\+'의 검색 결과

- 전방탐색을 사용하지 않은 정규표현식 'user-agent:.\{-}\s\S\+:'의 검색 결과

- 전방탐색을 사용한 정규표현식 'user-agent:.\{-}\(\s\S\+:\)\@='의 검색 결과

- 후방탐색을 추가한 정규표현식 '\(user-agent:\s\)\@<=.\{-}\(\s\S\+:\)\@='의 검색 결과
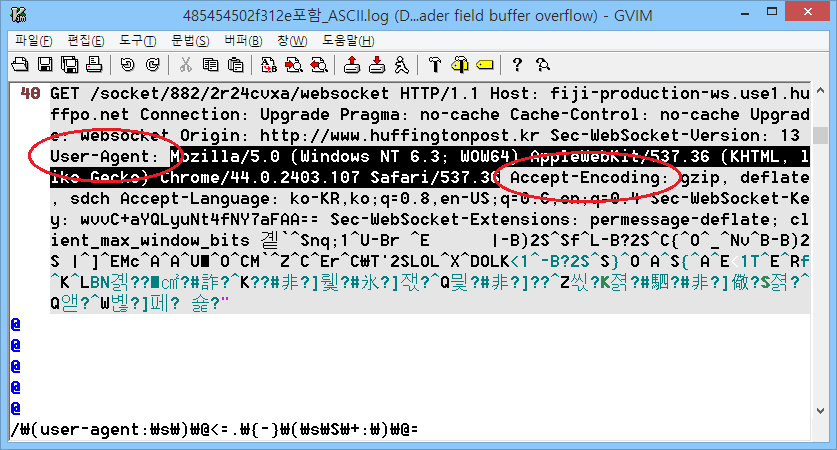

- 정규표현식 'user-agent:.\+'의 탐욕적 수량자 '\+'

- 정규표현식 'user-agent:.\{-}'의 게으른 수량자 '\{-}'
- '.\{-}'는 PCRE의 '.*?'와 동일하기 때문에 '0개 이상을 의미하는 '*' 수량자의 검사 범위를 최소로 제한, 결국 'user-agent:' 이후 '공백을 포함한 임의 문자'를 0개 검사함.

까다롭다고 생각되는 몇몇 정규표현식에 대해서 간단히 살펴봤다. '정규표현식 완전 해부와 실습(한빛미디어)'이란 책에 이런 문구가 있다.
정규표현식은 컴퓨터 세계의 맥가이버, 정규표현식을 아는 자가 문자열을 제압한다
그만큼 활용되는 분야가 다양하며, 효과가 크다는 의미일 것이다. 컴퓨터 환경에서 발생하는 데이터의 대부분은 '문자열'이기 때문.
과거(?) 보안 장비들은 Time, IP, Port 등 형식이 고정된, 즉 필드 추출이 쉬운 데이터의 정규화(Normalization)에만 집중하면서, 정작 중요한 의미를 담고 있는 '문자열'을 외면하는 실수를 범했다.
과거(?) 보안 장비들은 Time, IP, Port 등 형식이 고정된, 즉 필드 추출이 쉬운 데이터의 정규화(Normalization)에만 집중하면서, 정작 중요한 의미를 담고 있는 '문자열'을 외면하는 실수를 범했다.
하지만 빅데이터 유행 덕에 이제 꽤 많은 솔루션들이 정규표현식을 지원하며, 비정형 데이터의 필드 추출을 위해 정규표현식 사용을 권장하고 있다. 이런 상황에서 정규표현식의 활용 수준이 데이터 분석의 성패를 좌우한다고 하면 괜한 설레발일까?

댓글 없음:
댓글 쓰기