
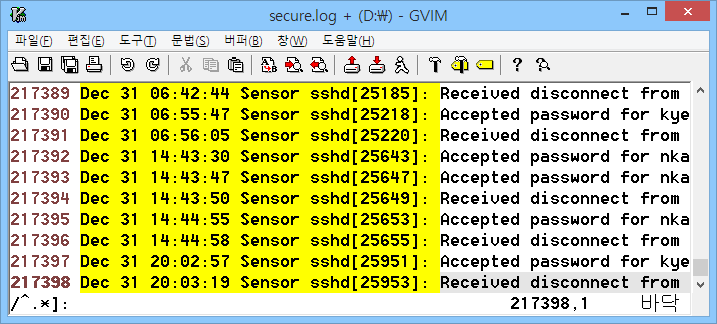
- 각 줄에서 첫 번째 시작(^)하는 문자부터 검색을 시작하며,
- 끝나는 문자는 ']:공백'이고,
- 검색 시작 위치와 끝 문자 사이에 임의 문자(.)가 0개 이상(*) 있음을 의미하는 정규표현식이다.

 |
| 검색 |
 |
| 치환 |
'sort u' 명령을 이용해서 중복 제거 후 정렬을 했음에도 유저명, IP 등의 세부 정보가 너무 다양해서 별 효과가 없다.
 |
| 중복 제거 후 정렬 |
메시지를 축약할 필요가 있다. 주요 키워드는 앞 부분에 위치하니 열세 자리 정도만 남겨두고 지워보면 어떨까? (왜 열세 자리냐고? 이것도 여러 번 삽질한 결과 ㅡㅡ)
 |
| 검색 |
그런데 문자열 치환 기능은 검색된 결과만을 치환, 즉 지울 수 있다. 그리고 우리가 원하는 결과는 앞 부분 열세 자리를 제외한 나머지 문자열을 지우는 것이다. 어떻게 해야 할까? 이럴 때 아주 유용한 정규표현식 기능이 바로 후방탐색.
구문 형식은 다음과 같으며 '패턴1'로 시작하는 '패턴2'만을 검색해준다. 즉 '패턴1'은 '패턴2'의 검색 기준으로만 동작하며 최종 검색 결과에는 포함되지 않는다.

앞 부분 열세 자리를 제외한 나머지 문자열만을 검색하는 정규표현식을 작성해보자. 사용된 검색어 '\(^.\{13}\)\@<=.*'는,
- 앞 부분 열세 자리(^.\{13})를 먼저 검색한 후,
- 해당 문자열의 종료 위치가 검색 시작 위치(\(^.\{13}\)\@<=)로 지정된,
- 모든 문자열(.*)을 검색하는 정규표현식이다.
 |
| debuggex.com |
 |
| 검색 |
검색이 되면 뭐다? 치환도 할 수 있다.
 |
| 치환 |
 |
| 중복 제거 후 정렬 |
sshd 프로세스는 열아홉 가지 유형의 메시지를 남겼으며, 나머지 프로세스도 같은 과정을 통해 발생 메시지 현황을 확인할 수 있다. 물론 정확하진 않다. 전체적인 윤곽만 확인했을 뿐.
그러나 대략적인 전체 구조와 의미 파악이라는 소기의 목적은 충분히 달성한 듯하다. 이제 해당 로그에서 무엇을, 어떻게 분석하면 좋겠다는 느낌적인 느낌이 오지 않는가?
이제까지의 삽질은 단지 삽질로 끝나지 않고, 반정형 데이터인 로그를 정형 데이터인 테이블로 바꾸는 작업(스키마 설계라고 하면 더 있어 보임)의 토대가 되어줄 것이며, 로그 분석이 아닌 데이터 분석을 가능하게 해줄 것이다.
다음 시간에는 VIM을 이용해서 적당히 나열된 로그를, 고정된 필드에 필요한 데이터가 적재된 테이블 구조로 바꾸는 과정을 진행해볼까 한다.
사족
VIM 정규표현식을 어렵게 만드는 요인 중 하나로 빈번하게 발생하는 예외 처리(\를 붙여야 메타 문자 또는 순수 문자로 인식) 상황을 들 수 있다.
대표적인 사례가 앞서 살펴본 후방탐색. 사용된 정규표현식 '\(^.\{13}\)\@<=.*'에서 소괄호는 '('와 ')' 모두, 중괄호는 '{'를 예외 처리해줘야 메타 문자로 인식하며, 후방탐색 구문에 포함되는 '@' 역시 예외 처리해줘야 기능이 동작한다.
이런 예외 처리가 빈번하게 발생하면 당연히 정규표현식을 쓰기도 힘들고, 읽기도 힘들어진다. 그런데 빈번한 예외 처리 상황을 피해갈 수 있는 방법이 있다. 바로 '매직 모드'. (전에도 한 번 얘기한 듯, 정리 좀 해야 하는데ㅡㅡ^)
매직 모드는 VIM 정규표현식의 예외 처리 상황을 반전시켜 준다. 즉 '\'와 순수 문자가 합쳐진 메타 문자에서 '\'를 제거해도 메타 문자로 인식한다.
단 이때 '순수 문자'는 알파벳을 제외한 기호 문자만을 의미하며, 아래와 같은 '\알파벳' 조합의 메타 문자는 매직 모드에서도 똑같이 사용한다.
 |
| 더 많은 메타 문자는 여기 |
사용법은 간단하다. 모든 정규표현식을 '\v'로 시작하면 된다.

다음 그림에서 사용된 정규표현식은 기존에 사용된 정규표현식보다 훨씬 간결하다. 쓰기 편하고 읽기 편해졌다는 얘기.
- 신규 : \v(^.{13})@<=.*
- 기존 : \(^.\{13}\)\@<=.*
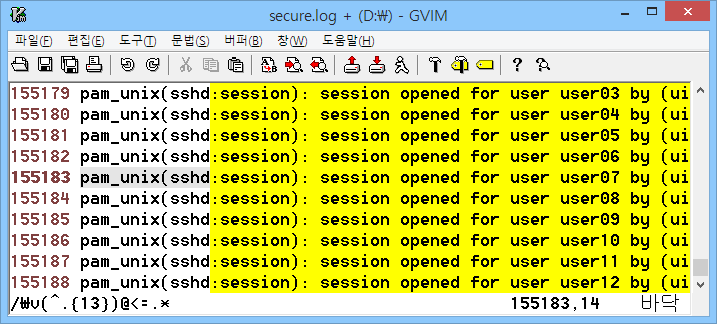 |
| 검색(매직 모드) |
항상 편한 건 아니고, 가끔 사람 헷갈리게도 하지만 대체적으로 많이 편해진다. 자꾸 쓰는 버릇을 들이면 VIM 정규표현식과 친해지는 데 많은 도움이 되지 않을까 한다.
관련 글

댓글 없음:
댓글 쓰기