
모든 트래픽은 반드시 IP 구조를 포함한 패킷이 발생한다. 이 얘기는 발생량 기반 탐지 룰은 기본적으로 모든 트래픽을 공격으로 탐지할 수 있으며 귀에 걸면 귀걸이, 코에 걸면 코걸이 되기 십상이라는 뜻이다.
 |
| 3.. 3번? |
이런 한계로 인해 발생량 기반 탐지 룰은 오탐이 대량 발생하는 결과를 가져온다. 다음은 어느 네트워크에서나 가장 흔하게 볼 수 있는, 웹 요청과 응답으로 이루어진 웹서핑 트래픽이 발생량 기반 공격으로 오인되는 사례이다.

- 출발지:목적지 구조가 N:1인 웹 요청 트래픽. DDoS 유형으로 많이 오인된다.

- 출발지:목적지 구조가 1:N인 웹 응답 트래픽. Port Scan 유형으로 많이 오인된다.
이렇다 보니 로그가 대량 발생할 수밖에 없음. 현장에 가보면 보안장비에서 발생량 기반 로그들이 쉴 새 없이 스크롤되는 광경을 쉽게 볼 수 있다. (네트워크 규모가 크면 패턴 기반 로그의 발생 상황도 별반 다르지 않음) limit나 both 등의 옵션이 존재하는 이유가 이해가 가는 대목.

로그가 이런 식으로 발생하면 일하기 싫은 게 인지상정이다. 그래서 많은 현장에서는 공격자 등의 기준으로 샘플링된 로그를 분석하며, 웹사이트 접속 지연 등 피해가 알려지지 않은 많은 로그들은 그냥 무시된다.
참고로 보안장비 운영과는 별도로 웹사이트 등 서비스 접속 상태에 대한 실시간 점검을 병행하는 현장들이 많다. DDoS 등의 공격에 대한 보안장비만의 대응이 어렵다는 방증.
사실 보안장비에서 DDoS 공격 탐지는 쉽지만, 탐지했다는 얘기는 이미 공격이 성공했을 가능성이 높기 때문에 공격이 본격화되기 전에 신속한 징후 포착이 매우 중요하다.
발생량 기반 로그를 효과적으로 처리할 수 있는 방법은 무엇일까? 기본은 오탐을 줄여서 불필요하게 발생하는 로그를 줄이는 것. 오탐이 줄수록 진짜 공격의 징후를 신속하게 포착해낼 확률은 높아진다.
먼저 오탐을 줄이자
어떻게 오탐을 줄일 것인가? 발생 현황을 분석해서 정상 트래픽임에도 탐지되는 경우를 찾아낸 후 탐지에서 제외, 즉 예외처리해야 한다. 결국 로그를 다 분석해야 한다는 말. 어느 세월에 다 하냐고?

답은 데이터베이스에 있다. 수십 년 동안 IT 세상을 지배해 온 관계형 데이터베이스는 그 이름에서 알 수 있듯이 다양한 데이터의 관계를 추적해서 데이터에 새로운 의미를 부여해준다. 데이터베이스는 최고의 데이터 분석 플랫폼이란 얘기.
보안장비와 연동된 데이터베이스를 잘만 활용하면 매우 효과적으로 로그의 전체 발생 현황을 파악할 수 있다. (데이터베이스가 없다면? 하루 빨리 데이터베이스가 구축되길 바라는 수 밖에) 사례를 보자.
운영중인 Snort에서 어느 날 'udp flood' 로그가 대량 발생했다. 다음은 Snort와 연동중인 Mysql 데이터베이스를 이용해서 발생 현황을 정리한 것이다. 7,000개가 넘는 로그가 발생했으며 공격자 IP 기준으로도 122개의 로그를 분석해야 한다.


IP간 발생 구조를 쉽게 파악할 수 있는 방법은 무엇일까? 다음 그림은 특정 출발지 IP가 30개의 목적지 IP와 연결되는 과정에서 가장 많은 'udp flood' 로그를 발생시켰음을 보여준다.
데이터베이스를 잘만 활용하면 7,000개나 122개의 로그를 죽 나열한 후, IP간에 일일이 작대기를 그려 넣는 수고를 하지 않고도 미처 보지 못하고 있던 새로운 의미를 발견할 수 있음을 알 수 있다.

쿼리문의 의미를 간단히 살펴보자.
select inet_ntoa(c.ip_src), count(distinct c.ip_dst), count(a.signature)
and b.sig_name = 'udp flood' ( 공격명 조건 )
and a.signature = b.sig_id ( a=b이고 )
and a.cid = c.cid and a.sid = c.sid ( a=c이면 b=c )
반대의 경우도 구해보자.

특정 목적지 IP가 92개의 출발지 IP와 연결되는 과정에서 가장 많은 'udp flood' 로그를 발생시켰으며, 두 경우의 로그 개수를 합치면 전체 로그의 발생 개수인 7,649개이다. 전체 로그의 IP 발생 구조가 파악되었다. 그림으로 표시하면 다음과 같다.

내친김에 포트 발생 구조도 파악해보자. 특정 출발지포트 및 목적지포트 기준의 로그 개수가 특정 출발지 IP 및 목적지 IP 기준의 로그 개수와 매우 유사하다. 전문용어로 아다리가 착착 맞아간다.
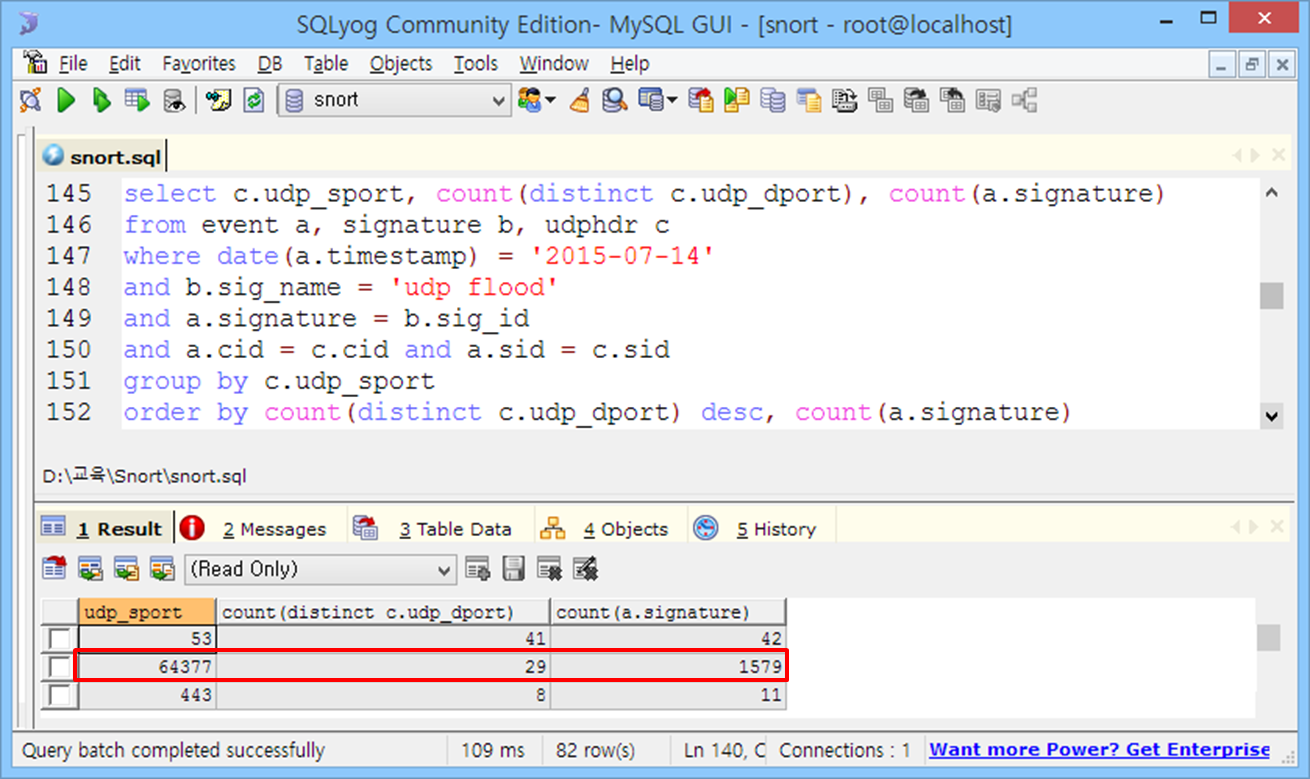

'udp flood' 로그의 IP 및 포트 발생 구조를 정리하면 다음과 같다.

언제 다 하나 싶었는데 벌써 끝났다. 물론 전체 로그의 발생 주체가 하나뿐인, 이렇게 행복한 경우는 좀 드물지만, 로그 발생 주체의 비중을 파악한 후, 높은 비중부터 정리해 나간다면 그리 어렵지도 않으며('80 대 20'의 법칙이 꽤 잘 적용됨), 오탐이 줄어든 만큼 빨라질 공격 대응을 생각한다면 반드시 해야만 한다.
이제 남은 건 확인된 IP 및 포트 발생 구조를 근거로 해당 트래픽의 탐지를 유지할지 말지 결정하는 것 뿐이다. (데이터 기반 의사 결정이 뭐 별건가?) 해당 트래픽을 예외처리하고 싶다면 기존 룰을 다음처럼 수정하면 된다. 물론 상용 보안장비도 IP, 포트 기준의 예외처리 기능을 지원한다.
alert udp !172.20.10.2 !64377 -> !172.20.10.2 !64377
(msg:”udp flood”;
threshold:type threshold, track by_dst, count:100, seconds:1;
sid:1000000;)
데이터 및 데이터 간 관계에 대한 이해가 있을 때 데이터베이스는 매우 쉬운 접근(너무나 직관적인 SQL)과 함께, 무한한 재해석의 가능성을 보여준다. 데이터에 대한 이해의 중요성을 알 수 있다.
어느 현장에서 오픈소스 기반의 빅데이터를 도입하고도 의미 있는 분석 결과가 통 나오지 않아, SAS 전문가를 초빙해서 데이터 분석을 의뢰한 사례가 있었다.
그러나 빅데이터로 수집한 로그를 다시 SAS에 부어가면서 분석을 시도했음에도 해당 전문가의 '무엇을', '왜' 분석해야 하는지에 대한 이해 부족으로 인해 데이터를 이해하는 보안 경험자가 분석을 주도해야 한다는 교훈만을 남겼다고 한다.
기존 데이터베이스의 한계를 지적하며 빅데이터에 열광하기 전에, 오래전부터 데이터베이스에 쌓여만 있던 데이터의 의미와 관계에 대해 이제라도 고민해볼 필요가 있음을 알려주는 사례가 아닐까 한다.
먼저 오탐을 줄이자
어떻게 오탐을 줄일 것인가? 발생 현황을 분석해서 정상 트래픽임에도 탐지되는 경우를 찾아낸 후 탐지에서 제외, 즉 예외처리해야 한다. 결국 로그를 다 분석해야 한다는 말. 어느 세월에 다 하냐고?

답은 데이터베이스에 있다. 수십 년 동안 IT 세상을 지배해 온 관계형 데이터베이스는 그 이름에서 알 수 있듯이 다양한 데이터의 관계를 추적해서 데이터에 새로운 의미를 부여해준다. 데이터베이스는 최고의 데이터 분석 플랫폼이란 얘기.
보안장비와 연동된 데이터베이스를 잘만 활용하면 매우 효과적으로 로그의 전체 발생 현황을 파악할 수 있다. (데이터베이스가 없다면? 하루 빨리 데이터베이스가 구축되길 바라는 수 밖에) 사례를 보자.
운영중인 Snort에서 어느 날 'udp flood' 로그가 대량 발생했다. 다음은 Snort와 연동중인 Mysql 데이터베이스를 이용해서 발생 현황을 정리한 것이다. 7,000개가 넘는 로그가 발생했으며 공격자 IP 기준으로도 122개의 로그를 분석해야 한다.


데이터베이스를 잘만 활용하면 7,000개나 122개의 로그를 죽 나열한 후, IP간에 일일이 작대기를 그려 넣는 수고를 하지 않고도 미처 보지 못하고 있던 새로운 의미를 발견할 수 있음을 알 수 있다.

쿼리문의 의미를 간단히 살펴보자.
select inet_ntoa(c.ip_src), count(distinct c.ip_dst), count(a.signature)
- 출발지 및 그 출발지와 연결된 목적지 개수와 로그 개수
- 데이터를 가져올 테이블
and b.sig_name = 'udp flood' ( 공격명 조건 )
and a.signature = b.sig_id ( a=b이고 )
and a.cid = c.cid and a.sid = c.sid ( a=c이면 b=c )
- 데이터 정합성 유지를 위한 테이블 join 조건
- 목적지와 로그 개수를 구하는 기준은 출발지
- 목적지 개수의 내림차순(desc) 정렬을 유지하면서 로그 개수 오름차순 정렬

특정 목적지 IP가 92개의 출발지 IP와 연결되는 과정에서 가장 많은 'udp flood' 로그를 발생시켰으며, 두 경우의 로그 개수를 합치면 전체 로그의 발생 개수인 7,649개이다. 전체 로그의 IP 발생 구조가 파악되었다. 그림으로 표시하면 다음과 같다.

내친김에 포트 발생 구조도 파악해보자. 특정 출발지포트 및 목적지포트 기준의 로그 개수가 특정 출발지 IP 및 목적지 IP 기준의 로그 개수와 매우 유사하다. 전문용어로 아다리가 착착 맞아간다.


'udp flood' 로그의 IP 및 포트 발생 구조를 정리하면 다음과 같다.

언제 다 하나 싶었는데 벌써 끝났다. 물론 전체 로그의 발생 주체가 하나뿐인, 이렇게 행복한 경우는 좀 드물지만, 로그 발생 주체의 비중을 파악한 후, 높은 비중부터 정리해 나간다면 그리 어렵지도 않으며('80 대 20'의 법칙이 꽤 잘 적용됨), 오탐이 줄어든 만큼 빨라질 공격 대응을 생각한다면 반드시 해야만 한다.
 |
| 참 쉽죠? |
이제 남은 건 확인된 IP 및 포트 발생 구조를 근거로 해당 트래픽의 탐지를 유지할지 말지 결정하는 것 뿐이다. (데이터 기반 의사 결정이 뭐 별건가?) 해당 트래픽을 예외처리하고 싶다면 기존 룰을 다음처럼 수정하면 된다. 물론 상용 보안장비도 IP, 포트 기준의 예외처리 기능을 지원한다.
alert udp !172.20.10.2 !64377 -> !172.20.10.2 !64377
(msg:”udp flood”;
threshold:type threshold, track by_dst, count:100, seconds:1;
sid:1000000;)
데이터 및 데이터 간 관계에 대한 이해가 있을 때 데이터베이스는 매우 쉬운 접근(너무나 직관적인 SQL)과 함께, 무한한 재해석의 가능성을 보여준다. 데이터에 대한 이해의 중요성을 알 수 있다.
어느 현장에서 오픈소스 기반의 빅데이터를 도입하고도 의미 있는 분석 결과가 통 나오지 않아, SAS 전문가를 초빙해서 데이터 분석을 의뢰한 사례가 있었다.
그러나 빅데이터로 수집한 로그를 다시 SAS에 부어가면서 분석을 시도했음에도 해당 전문가의 '무엇을', '왜' 분석해야 하는지에 대한 이해 부족으로 인해 데이터를 이해하는 보안 경험자가 분석을 주도해야 한다는 교훈만을 남겼다고 한다.
 |
| '신호와 소음' 중 |
기존 데이터베이스의 한계를 지적하며 빅데이터에 열광하기 전에, 오래전부터 데이터베이스에 쌓여만 있던 데이터의 의미와 관계에 대해 이제라도 고민해볼 필요가 있음을 알려주는 사례가 아닐까 한다.
그런 고민 없이, 너무나 직관적인 SQL조차 제대로 활용하지 않는 상태에서 아무리 데이터가 많은들 무슨 의미가 있을까?
관련 글
관련 글

댓글 없음:
댓글 쓰기