
파일 업로드 및 URL 삽입 등을 이용한 웹쉘 공격이 있다. 웹쉘은 웹 기반에서 시스템을 조작할 수 있는 도구의 통칭인데, 2008년 5월 KISA에서 ASP 기반 웹쉘 탐지 시그니처를 배포한 적이 있다.

그리고 해당 시그니처를 기반으로 Snort 룰 옵션을 이용하여 다음과 같은 IDS 탐지룰이 만들어진 사례가 있다.
alert tcp any any -> any 80 (content:"?Action="; nocase; pcre:"/\?Action\=(MainMenu|Show|Course|getTerminalInfo|ServerInfo|Cmd1?Shell|EditFile|Servu|sql|Search|UpFile|DbManager|proxy|toMdb)/i";)
|
복잡해 보이지만 해석하면,
①
alert tcp any any -> any 80
è 목적지 포트가 TCP 포트 80인 트래픽 중,
②
content:"?Action="; nocase;
è 대소문자 구분 없이('nocase;' 옵션) '?Action='이란 문자열 패턴이 포함된 트래픽을 1차 필터링
한 후,
③
pcre:"/\?Action\=(MainMenu|Show|Course|getTerminalInfo|ServerInfo|Cmd1?Shell|EditFile|Servu|sql|Search|UpFile|DbManager|proxy|toMdb)/i
è '?Action='
문자열 이후, 대소문자 구분 없이('/i' 옵션)
'|'로 구분된 각각의 문자열 패턴으로 2차 필터링 한다.
è pcre 옵션의 검사 범위를, content 옵션에 의해 '?Action='이란 문자열 패턴이 포함된 트래픽만으로 제한
참고로 2차
필터링은 정규표현식으로 작성됐는데 Regex Coach란
도구를 이용하면 좀더 빠른 이해가 가능하다. (또는 regex101.com)

패턴이 일치하면 공격일까?
'?Action='은 'URL?변수=값'으로 구성되는 URI(Uniform Resource Identifier)의 구성 요소(변수)이며, 개발 과정에서 얼마든지 자유로운 표현이 가능하다. 'Action'이란 패턴이 공격 의도로 사용되니, 해당 패턴이 발견되면 무조건 공격이다라고 말 할 수 없다는 얘기.
'?Action='은 'URL?변수=값'으로 구성되는 URI(Uniform Resource Identifier)의 구성 요소(변수)이며, 개발 과정에서 얼마든지 자유로운 표현이 가능하다. 'Action'이란 패턴이 공격 의도로 사용되니, 해당 패턴이 발견되면 무조건 공격이다라고 말 할 수 없다는 얘기.
즉 공격과 정상 트래픽이 한글과 영어처럼 다른 영역의 패턴을 사용하지 않는 이상, 룰과 일치하는 패턴은 공격의 가능성을 의미할 뿐, 확정할 수 없다는 뜻이다.
결국 모든 로그에 대해서 룰 패턴을 포함한 전체 메시지의 의미를 분석해야 한다. 1분에 하나씩 로그를 분석하면 1,140분 소요. 로그 전수 검사에 많은 인력과 시간이 필요함을 알 수 있다.

대량의 로그를 쉽게 분석할 수 있는 방법은 없을까? 발생한 로그는 해당 룰과 패턴이 일치하는 트래픽 패킷의 페이로드(Payload)를 저장한 것으로, 일반적으로 원시데이터라 부른다.
그런데 이 원시데이터는 일정한 규칙 없이 패턴들이 나열된 텍스트의 집합, 즉 비정형 데이터. 그리고 이 비정형 데이터를 일정한 규칙으로 분류된 정형 데이터로 변환하면, 즉 텍스트를 정규화하면 일괄적인 분석이 가능해진다.
다음은 이해를 돕기 위한 예시. A 패턴으로 동작하는 룰에 의해 발생한 로그를 분석하려면 먼저 원시데이터에서
A 패턴을 찾고, 해당 패턴이 전체 메시지에서 어떤 맥락으로 사용됐는지 파악해야 한다.
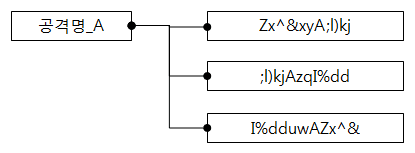
그런데 해당 원시데이터가 A 패턴을 기준으로 분류된 정형 데이터로 바꾸면 패턴의 맥락 파악이
훨씬 쉬워질 뿐만 아니라, 원시데이터를 하나 하나 분석하지 않고 일괄적으로
분석할 수 있다.

텍스트 정규화를 이용한 비정형 원시데이터 분석의 가능성을 알게 됐다. 다음은 실제 사례.
어떤 규칙으로 정규화할 것인가?
탐지 패턴을 기준으로 분류하는 것은 기본. 이때 제시된 사례처럼 웹 로그에 대해서 URI(웹 요청 정보), Referer(URI의 출발지), Host(URI의 목적지), User-Agent(요청 도구) 지시자 정보 기준의 분류를 시도하면 좀 더 정확한 분석이 가능해진다.
어떤 도구를 이용해서, 어디에서, 어디로, 어떤 정보를 전송했는지에 대한 전체 발생 현황을 쉽게 파악할 수 있기 때문.
변환 작업은 최종적으로 엑셀의 '텍스트 나누기' 기능을 이용할 것이며, 이를 위해서는 분류를 원하는 텍스트에 '구분 기호'를 추가해야 한다.
탐지 패턴을 기준으로 분류하는 것은 기본. 이때 제시된 사례처럼 웹 로그에 대해서 URI(웹 요청 정보), Referer(URI의 출발지), Host(URI의 목적지), User-Agent(요청 도구) 지시자 정보 기준의 분류를 시도하면 좀 더 정확한 분석이 가능해진다.
어떤 도구를 이용해서, 어디에서, 어디로, 어떤 정보를 전송했는지에 대한 전체 발생 현황을 쉽게 파악할 수 있기 때문.
변환 작업은 최종적으로 엑셀의 '텍스트 나누기' 기능을 이용할 것이며, 이를 위해서는 분류를 원하는 텍스트에 '구분 기호'를 추가해야 한다.
먼저 URI
웹브라우저 등 웹 요청 정보를 전송하는 도구는, 지원하는 HTTP의 버전을 URI 이후에 표시한다. 이 특성을 이용하면 로그에서 URI 정보만을 추출할 수 있다.
다음은 텍스트 에디터인 VIM에서 '/HTTP\/.*' 이란 검색 명령어를 이용하여 URI를 제외한 정보를 검색한 결과.
다음은 텍스트 에디터인 VIM에서 '/HTTP\/.*' 이란 검색 명령어를 이용하여 URI를 제외한 정보를 검색한 결과.

사용된 명령어의 의미는 다음과 같다.

검색이 가능하면 치환도 가능하다. 다음은 VIM의 문자열 치환 기능을 이용한 명령어(:%s/http\/.*//i)를 입력하여 URI를 제외한 모든 정보를 삭제한 결과. URI 정보만 추출됐음을 알 수 있다.

사용된 명령어의 의미는 다음과 같다.

Referer와 Host
Referer는 사용자가 과거에 요청한
URI이자, 현재 요청한 URI의 출발지 정보. 해당 값은 'Referer: ' 이후에 표시되며, 공백이
포함되지 않는다.
이런 특성을 이용하면 매우 쉽게 추출이 가능하다. 참고로 현재 요청한 URI의 목적지인 Host 정보 역시 값에 공백이 포함되지 않는다. 일단 검색 결과는 다음과 같다.
이런 특성을 이용하면 매우 쉽게 추출이 가능하다. 참고로 현재 요청한 URI의 목적지인 Host 정보 역시 값에 공백이 포함되지 않는다. 일단 검색 결과는 다음과 같다.

사용된 명령어의 의미는 다음과 같다.

URI 추출과 마찬가지로 검색 명령어를 이용해서 치환이 가능하다. 다음은 ':%s/referrer:\s\S\+/ㅋ&ㅋ/i' 명령어를 이용하여 치환한 결과.


구분 기호로 한글 자음인 'ㅋ'을 사용한 이유는 트래픽 정보를 표시하는데 사용되는 알파벳 등의 기호와 중복되는 것을 방지하기 위해서이며, 중복되지 않는다면 어떤 기호를 써도 상관 없다.
하지만 구분 기호가 통일되지 않고 중복된다면 텍스트 정규화는 실패할 것이다. 다음은 치환이 끝난 로그를 엑셀로 옮긴 후, '텍스트 나누기' 기능을 이용하는 과정.

다음을 보면 전체 로그가 Referer 정보를 기준으로 3개의 열로 분리됐음을 알 수 있다. 필요 없는 B와 D열의 정보는 삭제하면 된다.

Host 정보는 Referer와 같은 구조이기 때문에 같은 방식으로 분류하면 된다.
정확한 룰과 정확한 로그
텍스트 정규화를 이용해서 비정형 데이터를 정형 데이터로 바꿨다. 이제 분석을 해보자. 과연 해당 룰은 ASP 기반의 웹쉘 공격을 정확하게 탐지했을까? 엑셀의 필터링 기능을
이용하면 간편하게 원하는 패턴을 검색할 수 있다.

'?Action='로 URI 영역을 검색했는데 일치하는 패턴이 286개(25%)뿐이다. 왜 이런 결과가 나왔을까?

Referer 영역을 검색해보니 901개(78%)가 검색된다.

해당 룰은 '?Action=' 패턴을
필수로 검사하는데, 이때 사용된 Content 옵션은 패킷 페이로드의 전체 범위를 검사한다. URI 영역은
물론 Referer 등 HTTP 헤더를 포함한 데이터 영역
전체를 검사한 결과인 것.
'?변수=' 형식을 검사한 이유는 URI를 검사하겠다는 의미인데, 사용자가 과거에 요청한 URI인 Referer 영역까지 검사하면서 중복 탐지가 발생하고 있다. 결과적으로 로그 역시 중복으로 발생하고 있다.
'?변수=' 형식을 검사한 이유는 URI를 검사하겠다는 의미인데, 사용자가 과거에 요청한 URI인 Referer 영역까지 검사하면서 중복 탐지가 발생하고 있다. 결과적으로 로그 역시 중복으로 발생하고 있다.
룰 문제점 발견
아래와
같이 룰을 수정하면 하루에 발생한 로그량을 1,146개에서 286개로
줄일 수 있다. 'uricontent', 'http_uri'는 모두 패턴 검사 범위를 웹 요청 트래픽의 URI 영역으로 제한하라는 의미의 Snort 룰 옵션.
alert tcp any any -> any 80 (uricontent:"?Action="; nocase; pcre:"/\?Action\=(MainMenu|Show|Course|getTerminalInfo|ServerInfo|Cmd1?Shell|EditFile|Servu|sql|Search|UpFile|DbManager|proxy|toMdb)/i";)
|
alert tcp any any -> any 80 (content:"?Action="; nocase; http_uri; pcre:"/\?Action\=(MainMenu|Show|Course|getTerminalInfo|ServerInfo|Cmd1?Shell|EditFile|Servu|sql|Search|UpFile|DbManager|proxy|toMdb)/i";)
|
해당 룰은 ASP 기반에서
동작하는 웹쉘을 탐지하기 위한 것이다. 이번에는 다음 필터 조건을 이용하여 정확한 탐지가
이루어지고 있는지 확인해보자.

'?Action='을 포함한 286개의 로그 중 'asp?Action=' 패턴이 없는 로그는 67개(23%)이다. 참고로 엑셀에서
'?'를 일반 문자로 인식시키기 위해서 '~' 기호를 사용했다.

'php?action='
등 해당 룰이 정확하게 ASP 기반에서
동작하는 웹쉘을 탐지하지 않고 있음을 알 수 있다. 아래와 같이 룰을 수정하면 하루에 발생하는 로그량은 219개로 줄어든다.
alert tcp any any -> any 80 (uricontent:".asp?Action=";
nocase; pcre:"/\?Action\=(MainMenu|Show|Course|getTerminalInfo|ServerInfo|Cmd1?Shell|EditFile|Servu|sql|Search|UpFile|DbManager|proxy|toMdb)/i";)
|
alert tcp any any -> any 80 (content:".asp?Action="; nocase; http_uri; pcre:"/\?Action\=(MainMenu|Show|Course|getTerminalInfo|ServerInfo|Cmd1?Shell|EditFile|Servu|sql|Search|UpFile|DbManager|proxy|toMdb)/i";)
|
다음은 최종 확인된 193개의
웹쉘 공격 현황. 1,146개보다는 219개에서 193개(88%)의 공격을 찾는 것이 더 쉬울 것이다.

193개의 로그를 웹쉘 공격으로 판단한 근거는 무엇일까? 웹쉘 공격은 업로드한 웹쉘에
접속한 후, 다양한 명령을 'URI 변수=값' 구조를 통해 전송하면서 이루어진다.
그런데 정상 웹 서비스에서도 'Action'이란 변수를 사용할 수 있으며, 역시 변수의 값으로 'Show1File'이나 'MainMenu'란 값을 사용할 수 있다. 한마디로 개발자 마음.
일반적인 웹 서비스와 동작 방식이 똑같다는 얘기. 연재 초기에 룰 패턴을 포함한 전체 메시지의 의미를 분석해야 한다고 했는데, 그것만으로 부족할 때가 있다.
그런데 정상 웹 서비스에서도 'Action'이란 변수를 사용할 수 있으며, 역시 변수의 값으로 'Show1File'이나 'MainMenu'란 값을 사용할 수 있다. 한마디로 개발자 마음.
일반적인 웹 서비스와 동작 방식이 똑같다는 얘기. 연재 초기에 룰 패턴을 포함한 전체 메시지의 의미를 분석해야 한다고 했는데, 그것만으로 부족할 때가 있다.
가장 간단한 방법은 해당 웹서버 관리자에게 'shell.asp'가 해당 웹사이트에서 정상 서비스하는 컨텐츠인지 물어보는 것. 그런데 현실적으로 힘들다면?
웹 서비스와 동작 방식이 똑같기 때문에 그냥 접속해보면 된다. 다음은 해당 웹쉘 접속 결과. 정체불명의 로그인 페이지로 연결된다.

다음은 Wireshark를 이용해서 실제 공격자의 로그인 시도 트래픽을 캡쳐한 결과. 로그인 패스워드가 'sectest'임을 알 수 있다.

참고로 일반적인 웹 서비스는 데이터베이스와 연동하여 패스워드 인증
체계를 구현하지만 웹쉘 공격은 웹쉘 파일만으로 이루어지기 때문에 공격자들은 대부분 다음처럼 파일 자체에 패스워드를 심어놓는다.

다음은 웹쉘 로그인에 성공한 화면. 해당 웹쉘이 중국에서 만들어졌으며, 파일/디렉토리 접근이 가능함을 알 수 있다.

나가며
로그 분석이 싱겁게 끝나 버렸다.
원시데이터를 체계적으로 분석할 수 있는 환경만 마련된다면 정작 로그 분석은 그리 어렵지 않다는 얘기. 이처럼 로그 전수 검사를 실시하면,
① 룰의 문제점을 파악할
수 있고,
② 이를 통해 룰의 정확도를
높일 수 있으며,
③ 높아진 룰 정확도에 의해
로그 발생량이 줄면서 더 많은 공격을 더 빨리, 그리고 더 쉽게 찾아낼 수 있게 된다.
대량으로 발생하는 로그에 대해 그 동안 보안 분야가 체계적으로 대응하지
못했던 것이 사실이다. 최근에는 빅데이터가 유행하면서 빅데이터 솔루션을 이용하면 체계적으로 대량 로그에
대응할 수 있다는 주장도 제기되고 있다.
그러나 구글의 '독감 예측 시스템'이 대표적 빅데이터 사례로 꼽힐 수 있었던 이유는 검색어라는 데이터가 검색어
발생 양상이라는 분석 목적에 부합하는, 즉 정확한 데이터였기 때문이다.
우리는 보안로그 데이터에 부정확한 로그가 매우 많다는 사실을 이미 알고 있다. 먼저 데이터를 정확하게 만드는 시도 없이 빅데이터 솔루션으로
데이터만을 수집한다면, 더 거대해진 쓰레기데이터 속에서 공격을 찾아 헤매게 될 것이다.
결국 로그 전수 검사를 통해 룰 정확도를 높이는 것이 보안 관점에서 올바른 빅데이터 활용이며, 그러한 경험이 충분히 쌓인 상태에서 더 많은 데이터를 활용하게 될 때, 더 큰 통찰을 이끌어내는 것도 가능해질 것이다.
관련 글
결국 로그 전수 검사를 통해 룰 정확도를 높이는 것이 보안 관점에서 올바른 빅데이터 활용이며, 그러한 경험이 충분히 쌓인 상태에서 더 많은 데이터를 활용하게 될 때, 더 큰 통찰을 이끌어내는 것도 가능해질 것이다.
관련 글

댓글 없음:
댓글 쓰기